目次
代表値
データを要約して伝える必要がある場合,データの特徴を表す値をデータの代表値として用いることがあります.よく使われる代表値として3つ紹介します.
- 平均値(mean)
- 中央値(median)
- 最頻値(mode)
平均値(mean)
一番よくつかわれる代表値です.
ここでいう平均とは相加平均または算術平均のことです.その他の意味での平均については別途紹介します.
全てのデータの値の総和を求め, データの個数で割ると平均が求まります.
生データから平均を求める
$n$個のデータを$x_1 , x_2 , \cdots ,x_n$とした場合に平均値$\overline{x}$は,
\overline{x} = \frac{x_1+x_2+\cdots+x_n}{n}
\end{align}
となります.
観測値と度数の表から平均を求める
もしも, すでにデータを観測値と度数で整理できていればその情報を使って平均を簡単に求めることができます.
例えば$200$人に1週間のうちお酒を飲む日数をアンケートをとり,次のような表にデータが整理できている場合を考えます.
\text{日数}&\text{人数} \\ \hline
0& 15 \\
1& 32 \\
2& 75 \\
3& 35 \\
4& 28 \\
5& 10 \\
6& 3 \\
7& 2 \\ \hline
\text{合計} & 200
\end{array}
この表からお酒を飲む日数の平均を求めるには,各行の「日数×人数」を計算してその総和を$200$で割ればよいです.
\overline{x} &= \frac{0\times 15 + 1\times 32 + 2\times 75 + 3 \times 35 + 4\times 28 + 5\times 10 + 6 \times 3 + 7 \times 2}{200}\lnl
&= 2.405
\end{align}
度数分布表から平均を求める
度数分布表から平均を求めます.度数分布表から求まる平均は平均の近似値です.なぜならば,度数分布表にする際に同じ階級にあるデータは一まとまりにされるからです.
度数分布表とはこういうものでした.
\text{階級}&\text{階級値} & \text{度数} \\ \hline
a_0\sim a_1 & x_1 & f_1 \\
a_1\sim a_2 & x_2 & f_2 \\
\vdots & \vdots & \vdots \\
a_{n-1}\sim a_n & x_n & f_n \\ \hline
\text{計} & \text{—} & N \\
\end{array}
この表に対する平均$\overline{x}$は,
\overline{x} = \frac{1}{n} \sum_{i=1}^n x_if_i
\end{align}
で求められます.
具体的なデータを用いて計算してみましょう.次の度数分布表のデータの平均を求めてみます.
\begin{array}{c*2{|c}}
\text{階級}&\text{階級値} & \text{度数} \\ \hline
0\text{点以上}10\text{点未満}& 5 & 2 \\
10\text{点以上}20\text{点未満}& 15 & 1 \\
20\text{点以上}30\text{点未満}& 25 & 4 \\
30\text{点以上}40\text{点未満}& 35 & 20 \\
40\text{点以上}50\text{点未満}& 45 & 37 \\
50\text{点以上}60\text{点未満}& 55 & 76 \\
60\text{点以上}70\text{点未満}& 65 & 72 \\
70\text{点以上}80\text{点未満}& 75 & 58 \\
80\text{点以上}90\text{点未満}& 85 & 25 \\
90\text{点以上}100\text{点以下}& 95 & 5 \\ \hline
\text{計} & \text{—} & 300 \\
\end{array}
まず,表を拡張し「階級値×度数」の列を追加します.各行を計算し合計も計算します.
\begin{array}{c*3{|c}}
\text{階級}&\text{階級値} & \text{度数} & \color{red}{\text{階級値}\times\text{度数}} \\ \hline
0\text{点以上}10\text{点未満}& 5 & 2 &\color{red}{10} \\
10\text{点以上}20\text{点未満}& 15 & 1 &\color{red}{15} \\
20\text{点以上}30\text{点未満}& 25 & 4 &\color{red}{100} \\
30\text{点以上}40\text{点未満}& 35 & 20 &\color{red}{700} \\
40\text{点以上}50\text{点未満}& 45 & 37 &\color{red}{1665} \\
50\text{点以上}60\text{点未満}& 55 & 76 &\color{red}{4180} \\
60\text{点以上}70\text{点未満}& 65 & 72 &\color{red}{4680} \\
70\text{点以上}80\text{点未満}& 75 & 58 &\color{red}{4350} \\
80\text{点以上}90\text{点未満}& 85 & 25 &\color{red}{2125} \\
90\text{点以上}100\text{点以下}& 95 & 5 &\color{red}{475} \\ \hline
\text{計} & \text{—} & 300 & \color{red}{18300} \\
\end{array}
「階級値×度数」の合計の$18300$を「度数」の合計の$300$で割った$61$が平均値です.
中央値(median)
平均値はどのようなデータに対してもデータを代表する値になるとは限りません.
例えば,$ 1 , 1 , 2 , 2, 2 ,3 , 3, 12, 15$というようなデータに対して平均を求めると$4.56$ですが$9$個中$7$個のデータがこれを下回るような状況になってしまいます.
上の例のようにデータの分布に偏りがあるような場合にはデータのちょうど真ん中に位置する値を代表値として採用することがいいことがあります.これを中央値といいます.
生データから中央値を求める
データの個数が奇数か偶数かで少し定義が異なります.
データを値が小さい順にソートしてあるものとします.つまり,
x_1 \le x_2 \le \cdots \le x_n
\end{align}
となっているものとします.
(i)データの個数が奇数の場合
データの個数$n$は整数$k$を用いて$n=2k+1$と表せます.このとき,中央値$\tilde{x}$は,
\tilde{x} = x_{k+1}
\end{align}
(ii)データの個数が偶数の場合
データの個数$n$は整数$k$を用いて$n=2k$と表せます.このとき,中央値$\tilde{x}$は,
\tilde{x} = \frac{1}{2}(x_{k} + x_{k+1})
\end{align}
度数分布表から中央値を求める
度数分布表で使われる記号の意味はこちら.
\begin{array}{c*5{|c}}
\text{階級}&\text{階級値} & \text{度数} & \text{相対度数} & \text{累積度数} & \text{累積相対度数} \\ \hline
a_0\sim a_1 & x_1 & f_1 & f_1/N & F_1 & F_1/N\\
a_1\sim a_2 & x_2 & f_2 & f_2/N & F_2 & F_2/N\\
\vdots & \vdots & \vdots & \vdots& \vdots& \vdots \\
\color{blue}{a_{j-2}\sim a_j-1} &\color{blue}{ x_{j-1}} &\color{blue}{ f_{j-1}} &\color{blue}{ f_{j-1}/N }& \color{blue}{F_{j-1} }&\color{blue}{ F_{j-1}/N}\\
\color{red}{a_{j-1}\sim a_j} &\color{red}{ x_j} &\color{red}{ f_j} &\color{red}{ f_j/N }& \color{red}{F_j }&\color{red}{ F_j/N}\\
\vdots & \vdots & \vdots & \vdots& \vdots& \vdots \\
a_{n-1}\sim a_n & x_n & f_n & f_n/N & F_n & F_n/N\\ \hline
\text{計} & \text{—} & N & 1 & \text{—} & \text{—}\\
\end{array}
まず,累積度数を見てどの階級に中央値が来るか確認します.
この例では赤で示した$j$番目の階級に中央値があるとすると,累積分布度数は次を満たすはずです.
\color{blue}{F_{j-1}}\color{black}{ < \frac{N}{2} \le} \color{red}{F_{j}}
\end{align}
式で書くと仰々しいですが,累積度数がちょうど真ん中以上になる階級だという意味です.
次に,この階級の中でどこに中央値が位置するかを求める必要があります.
その際,階級の中にデータが均一に配置されていると仮定して求めることにすると,中央値$\tilde{x}$は,
\tilde{x} = a_{j-1} + (a_j- a_{j-1})\frac{\cfrac{N}{2} – F_{j-1}}{f_j}
\end{align}
となります.これを求めてみましょう.上記の仮定のもとで,以下の順に考えて求めます.
- 中央値がこの階級の下から何番目に位置するか求める
- 1.をこの階級の度数で割ると中央値が階級の下から何割に位置するか求まる
- 2.に階級の幅を掛けると中央値が階級の下からどれだけ離れた位置にあるか求まる
- 3.に階級の下限を足すと中央値が求まる
1.中央値がこの階級の下から何番目に位置するか求める
中央値は$\cfrac{N}{2}$番目にあります.($N$が奇数だと割り切れませんが,均一に分布しているという仮定のもとであれば計算上はこれで大丈夫です)
この階級の下からの位置を求めるには,前階級の再上限を引けばいいですね.
つまり,中央値がこの階級の下からの位置$n_0$は,
n_0 = \frac{N}{2} – F_{j-1}
\end{align}
2.「1.」をこの階級の度数で割ると中央値が階級の下から何割に位置するか求まる
これは単純にこの階級の度数$f_j$で割るだけです.
\frac{n_0}{f_j} = \frac{\cfrac{N}{2}-F_{j-1}}{f_j}
\end{align}
3.「2.」に階級の幅を掛けると中央値が階級の下からどれだけ離れた位置にあるか求まる
階級の幅が均一で既知であればそれを掛ければよいです.今回は幅$h = a_j – a_{j-1}$として,
h\frac{n_0}{f_j} = (a_j-a_{j-1})\frac{\cfrac{N}{2}-F_{j-1}}{f_j}
\end{align}
4.「3.」に階級の下限を足すと中央値が求まる
階級の下限は$a_{j-1}$でした.これを足せば$\tilde{x}$は
\tilde{x} = a_{j-1} + (a_j-a_{j-1})\frac{\cfrac{N}{2}-F_{j-1}}{f_j}
\end{align}
となり求まりました.
例.度数分布表から中央値を求める例題
次の度数分布表から中央値を求めてみます.
\begin{array}{c*3{|c}}
\text{階級}&\text{階級値} & \text{度数} & \text{累積度数} \\ \hline
0\text{点以上}10\text{点未満}& 5 & 2 & 2 \\
10\text{点以上}20\text{点未満}& 15 & 1 & 3 \\
20\text{点以上}30\text{点未満}& 25 & 4 & 7 \\
30\text{点以上}40\text{点未満}& 35 & 20 & 27 \\
40\text{点以上}50\text{点未満}& 45 & 37 & 64 \\
\color{blue}50\text{点以上}60\text{点未満}& \color{blue}55 & \color{blue}76 & \color{blue}140 \\
\color{red}60\text{点以上}70\text{点未満}& \color{red}65 &\color{red} 72 & \color{red}212 \\
70\text{点以上}80\text{点未満}& 75 & 58 & 270 \\
80\text{点以上}90\text{点未満}& 85 & 25 & 295 \\
90\text{点以上}100\text{点以下}& 95 & 5 & 300 \\ \hline
\text{計} & \text{—} & 300 & \text{—} \\
\end{array}
$\cfrac{N}{2} = 150$ですから,青く書いた行は累積度数が足りず,赤く書いた行で初めて超えることがわかります.つまり中央値は赤い行にあります.
従って中央値$\tilde{x}$は,
\tilde{x} &= a_{j-1} + (a_j – a_{j-1})\frac{\cfrac{N}{2} – F_{j-1}}{f_j}\lnl
&= 60 + (70-60)\frac{150-140}{72}\lnl
&=61.4
\end{align}
と求まります.
最頻値(mode)
どのデータが一番よく表れるのかを表す代表値として最頻値(mode)があります.
最頻値とはその名の通り,データの中で最も多く表れている値です.
最も多く表れる値が複数ある場合,いずれも最頻値となりますが,代表値として複数あるのは違和感があります.そのようなケースで最頻値を代表値として扱うのは不適切な感じがします.
生データから最頻値を求める
一番多く表れる値を最頻値とします.
例.生データから最頻値を求める例題
100個のデータの最頻値を求めましょう.
48 , 60 , 53 , 58 , 39 , 54 , 46 , 51 , 54 , 63 , 52 , 63 , 33 , 56 , 50 , 54 , 21 , 26 , 49 , 36 , 61 , 53 , 46 , 42 , 42 , 55 , 45 , 58 , 69 , 48 , 51 , 46 , 57 , 36 , 36 , 55 , 78 , 46 , 41 , 44 , 43 , 63 , 58 , 63 , 45 , 54 , 65 , 52 , 55 , 45 , 60 , 46 , 58 , 45 , 41 , 42 , 47 , 59 , 60 , 46 , 39 , 64 , 43 , 52 , 58 , 51 , 49 , 37 , 58 , 47 , 41 , 51 , 40 , 55 , 57 , 52 , 48 , 34 , 44 , 54 , 55 , 42 , 45 , 33 , 51 , 46 , 49 , 44 , 63 , 69 , 47 , 41 , 69 , 61 , 32 , 54 , 57 , 60 , 64 , 37 ,
各数字の出現回数を数えます.
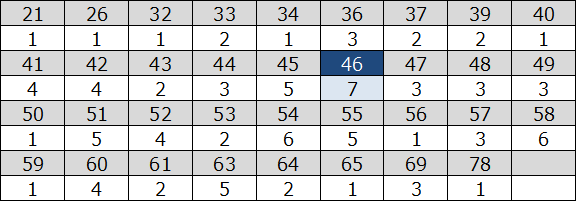
最頻値は$7$回出現する$46$でした.
度数分布表から最頻値を求める
一番多い度数を持つ階級の階級値を最頻値とします.
例.度数分布表から最頻値を求める例題
次の度数分布表から最頻値を求めてみます.
\begin{array}{c*3{|c}}
\text{階級}&\text{階級値} & \text{度数} & \text{累積度数} \\ \hline
0\text{点以上}10\text{点未満}& 5 & 2 & 2 \\
10\text{点以上}20\text{点未満}& 15 & 1 & 3 \\
20\text{点以上}30\text{点未満}& 25 & 4 & 7 \\
30\text{点以上}40\text{点未満}& 35 & 20 & 27 \\
40\text{点以上}50\text{点未満}& 45 & 37 & 64 \\
50\text{点以上}60\text{点未満}& 55 & 76 & 140 \\
60\text{点以上}70\text{点未満}& 65 &\ 72 & 212 \\
70\text{点以上}80\text{点未満}& 75 & 58 & 270 \\
80\text{点以上}90\text{点未満}& 85 & 25 & 295 \\
90\text{点以上}100\text{点以下}& 95 & 5 & 300 \\ \hline
\text{計} & \text{—} & 300 & \text{—} \\
\end{array}
一番度数の多い階級は[50点以上60点未満]ですのでその階級値の$55$が最頻値となります.